Cultural Differences
Colors or Colours? Miles or Kilometers? Drive Left or Drive Right?
Subtle cultural differences shape our perception, and in turn, how we express ourselves.
From our previous round of exploration we have hypothesized that stroke-level details within a given drawing may help uncover potential demographical information. But how do we put that to the test?
One analysis on a subset of the Quickdraw dataset suggests that language influences how abstract shapes (namely circles) are drawn. We were inspired by their approach and decided to train models for each potential data category with the continents as the labels.
Building a Strong Predictor
Before we do that, we will need to start with the baseline model, and start building from there.
To make sure we can learn something from the doodles, we started with the original task: predicting the category from users' drawings. Although it seems to be a straightforward task, there are still many issues to consider before we train the model. These issues range from parsing the input data from the source to constructing a suitable model. During the inference phase, we will also need to be able to shape the drawing we capture from the canvas using the exact same method as Google.
The input data is parsed through a MapReduce routine, with the Map phase gathering and preprocessing the data, and the Reduce phase grouping datapoints based on their respective key (the label).
The model composes of a combined CNN/RNN/FC layout. We have more more details on the architecture and how we trained it in the Machine Learning Section
The Original QuickDraw
We invite you try out our custom trained baseline model (94.9% accuracy on test set) using the following 20 categories:
- butterfly
- banana
- alarm clock
- lightning
- pizza
- spider
- palm tree
- flower
- fish
- chair
- cloud
- basketball
- eyeglasses
- ice cream
- scissors
- skateboard
- lollipop
- feather
- book
- light bulb
Cultural Differences (Continued)
Now that we have successfully completed a round of model training, we can be more confident that training models may in fact yield accuracies that reflect how "good" we could possibly do given the training dataset.
I like to think of the final accuracy somewhat reflective of the amount of entropy that the training dataset affords us to possibly reduce. This assumes that the model utilizes robust regularization techniques and is given enough training cycles. That is to say that given a specific category of drawings, there is only so much cultural differences you can learn: the rest is just random guessing.
In the process of exploring the dataset, we came across a peculiar difference that we fortuitously stumbled upon: rectangles are drawn significantly differently in the eastern world compared to the rest.
China, Japan, and Korea are all eastern countries that use block-based characters (logograms). In fact, these countries are often grouped together under the acronym CJK for localization purposes. Among these languages, they all have a very common square-like base-character. In Chinese this is the kou (口), in Japanese this is the ro (口), and in Korean this is the ng (ㅁ).
Our team identifies that these square-like characters all have a consistent stroke-pattern. See the diagram below:
kou
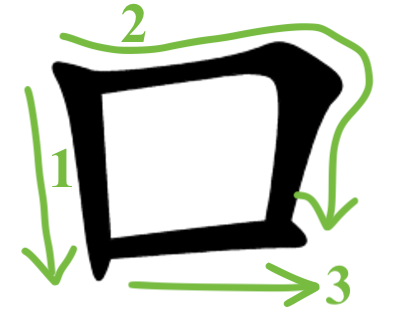
ro
ng
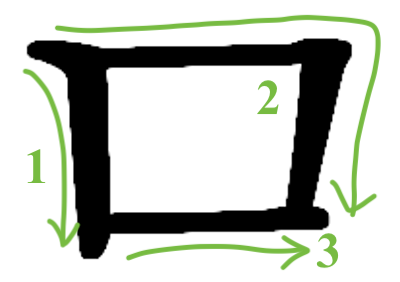
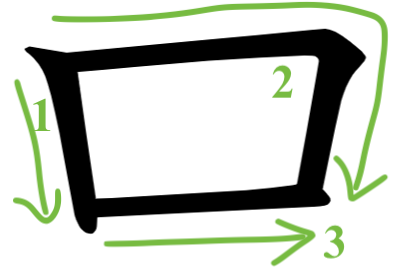
Let us extract all the eastern square doodles and the western square doodles and put them side by side for comparison.
Eastern doodle of a square:
Western doodle of a square:
Wow! We observe that our hypothesis is consistent with what we find in the real dataset. That is to say that Asian countries favor drawing square differently compared to Westerners. This is an exciting discovery that we might be able to leverage.
We trained our model on the square doodle dataset on the (ASIA, EUROPE, NORTH AMERICA) labels for 50 thousand steps and obtained a 44.0% accuracy. This is not ideal, but we are just getting started.
Beyond Squares
Since training individual models for over 300 different topics is far too computationally intensive, we cherry-picked 34 categories to narrow down our scope.
Here are the training results: (Click on the field name to sort)
It is important to clarify what the accuracy really means. After all, any unintelligent model could obtain 33.3% accuracy just by pure guessing since we have 3 labels of equal distribution.
In this case, we measure the increase in accuracy over 33.3% as the effectiveness of the model. Since we assume our methods result in an ideal model, the above table indicates which categories provide the best features for distinguishing demographics.
Making Sense of Shapes
Sorting the table and looking at the top-3 predictor candidates (Power outlet, Traffic light, and Church), we notice a trend. These topics are often depicted in different ways across different cultures.
Don't just take our word for it though. Inspired by our friends at Forma Fluens, we humans are visual creatures: let us show you the blended image from each of the major continents.
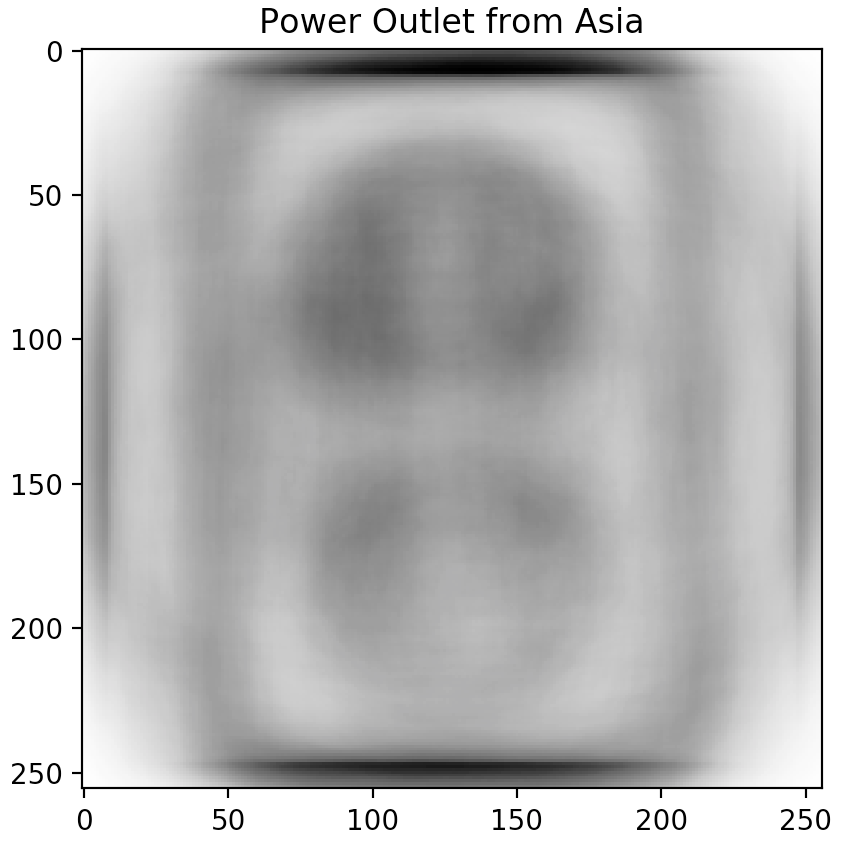
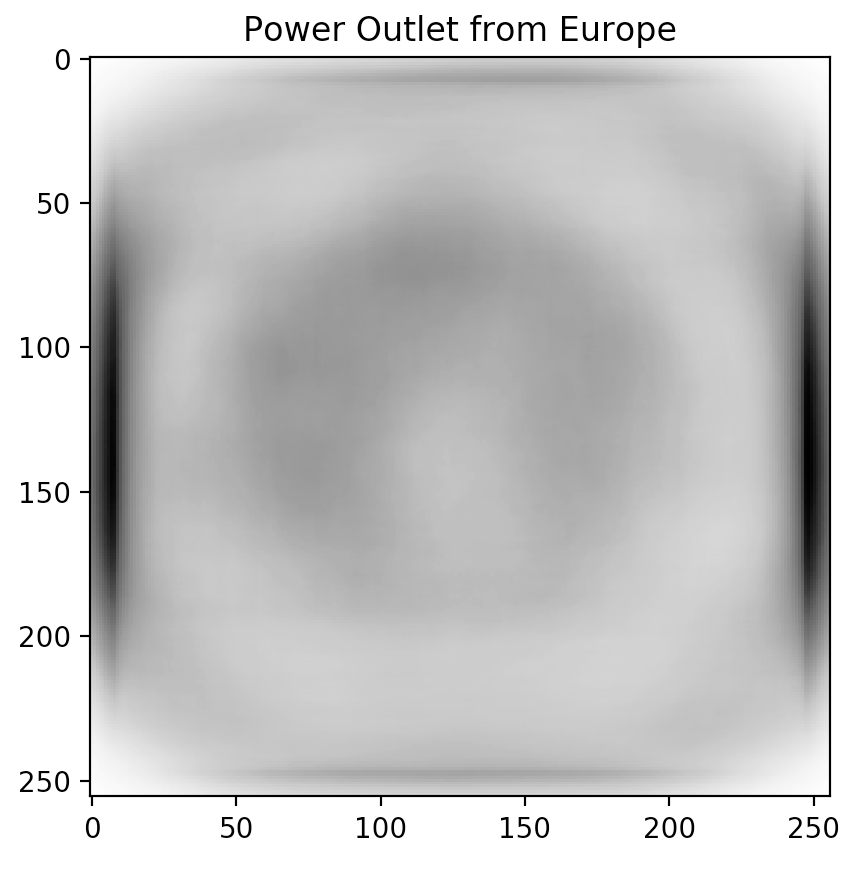
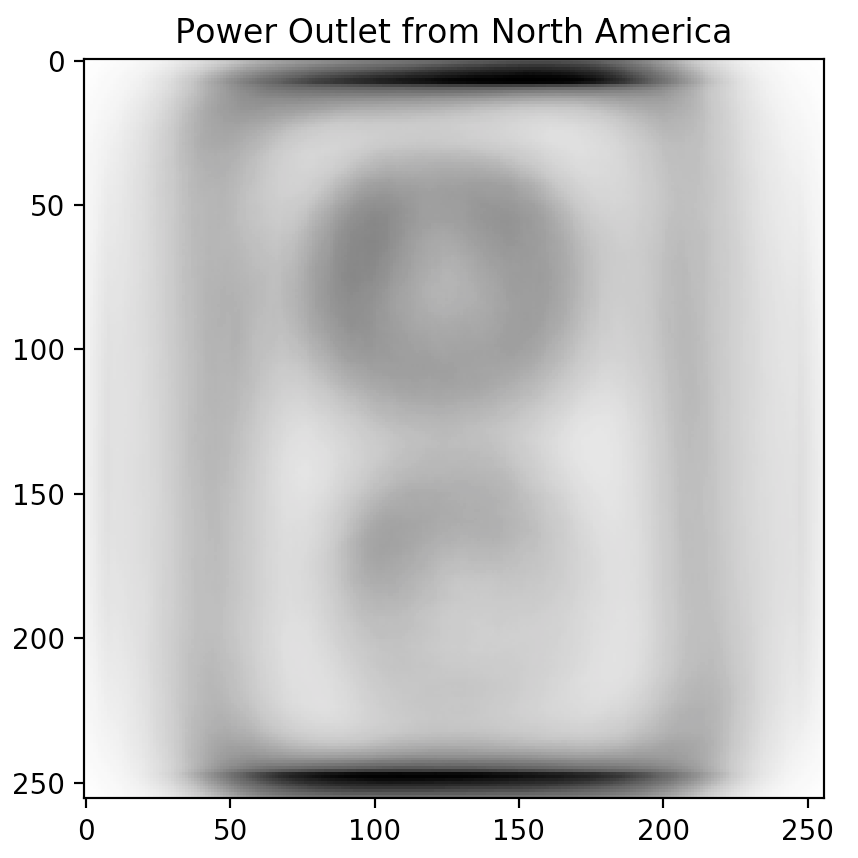
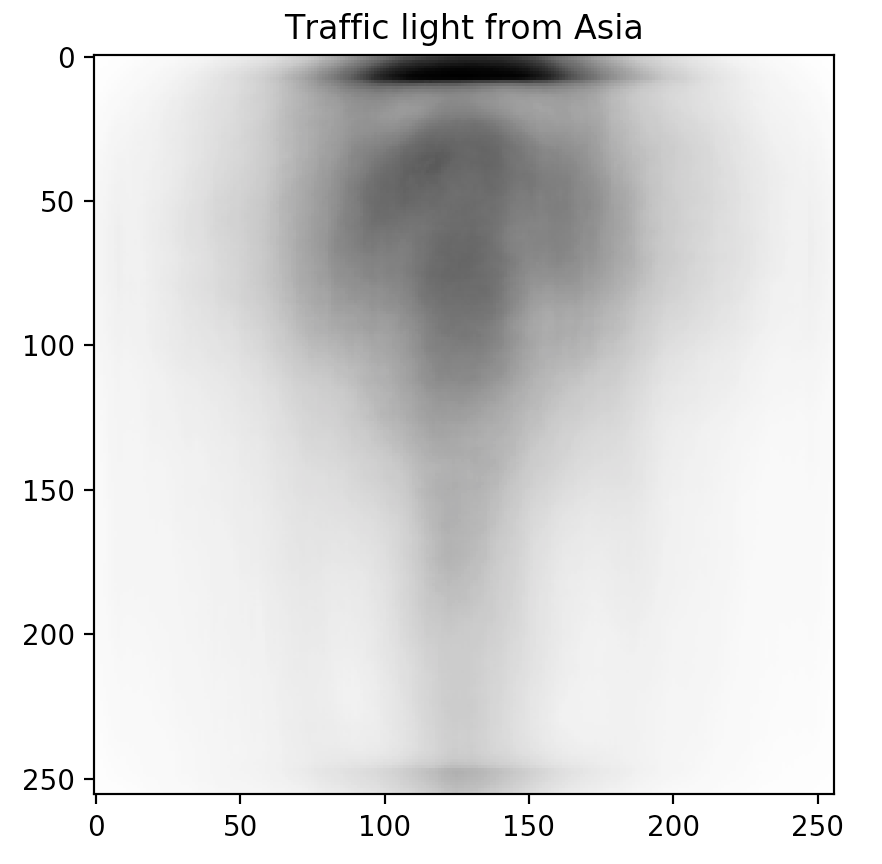
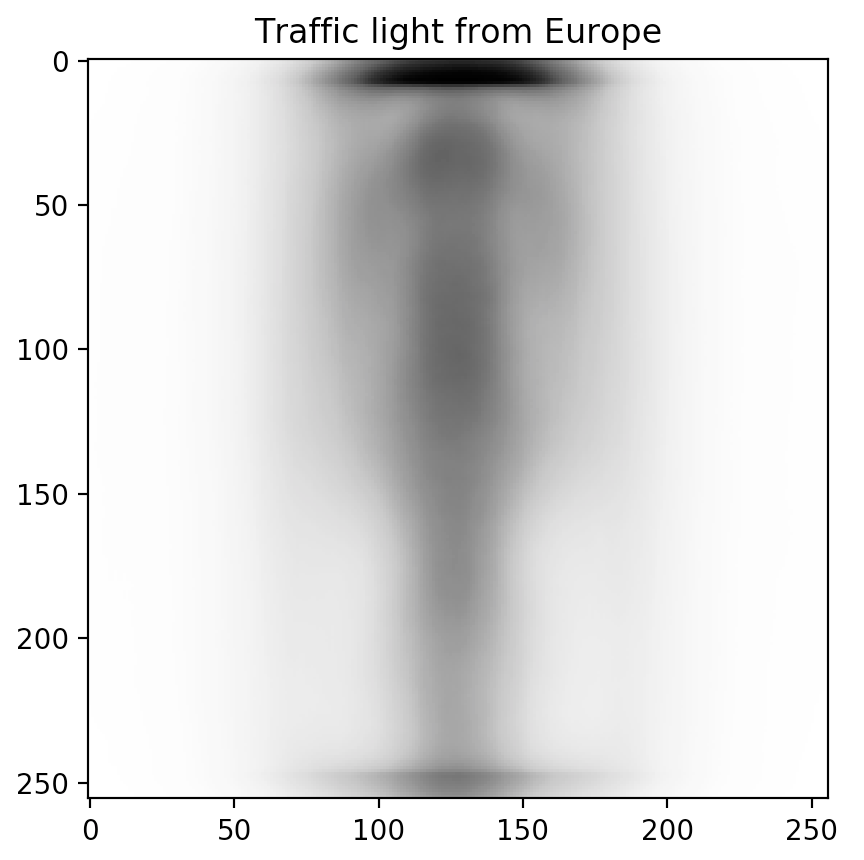
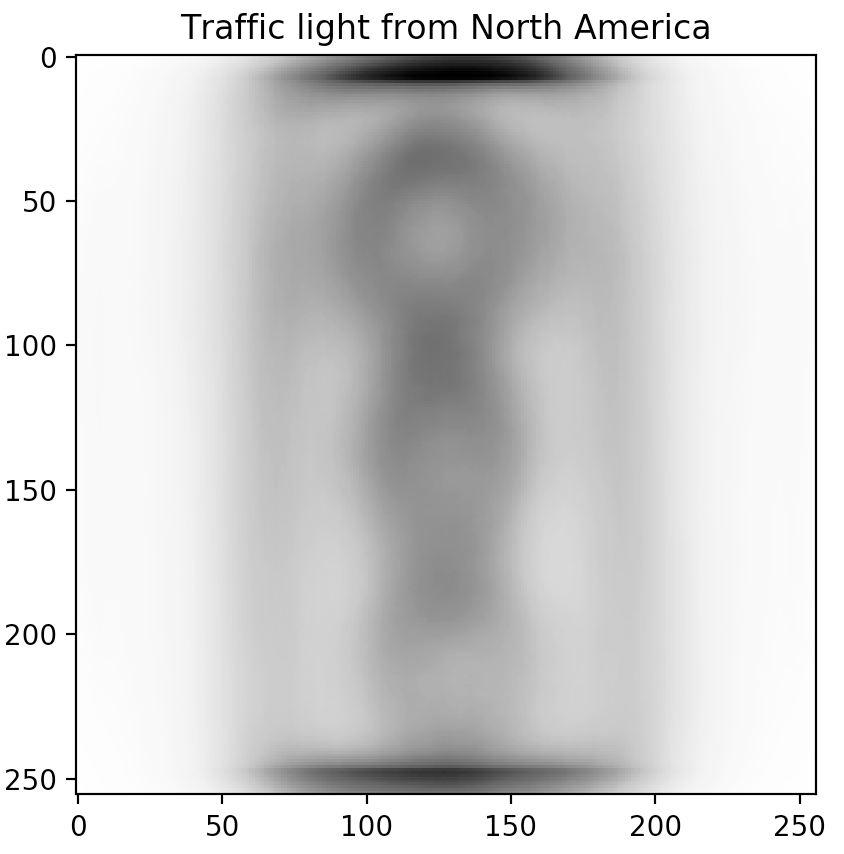
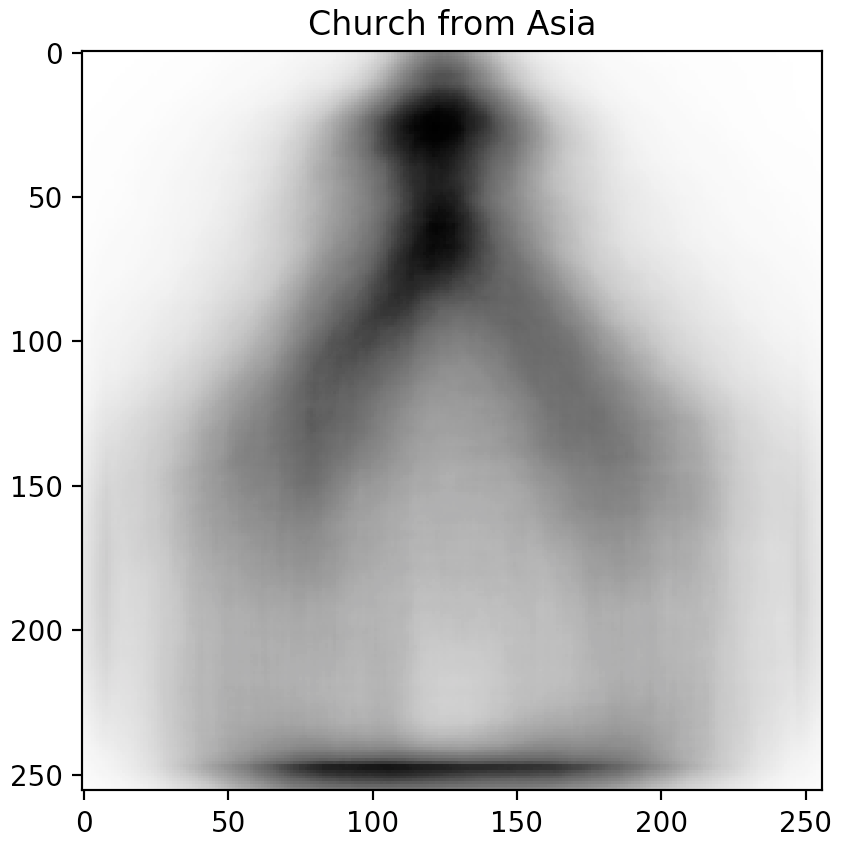
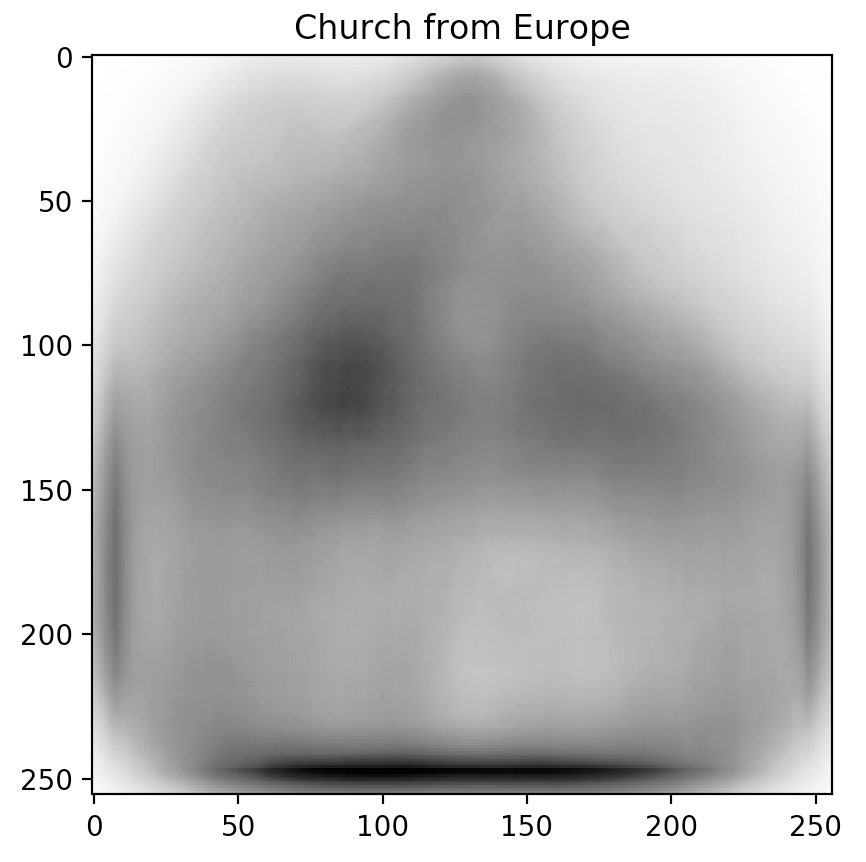
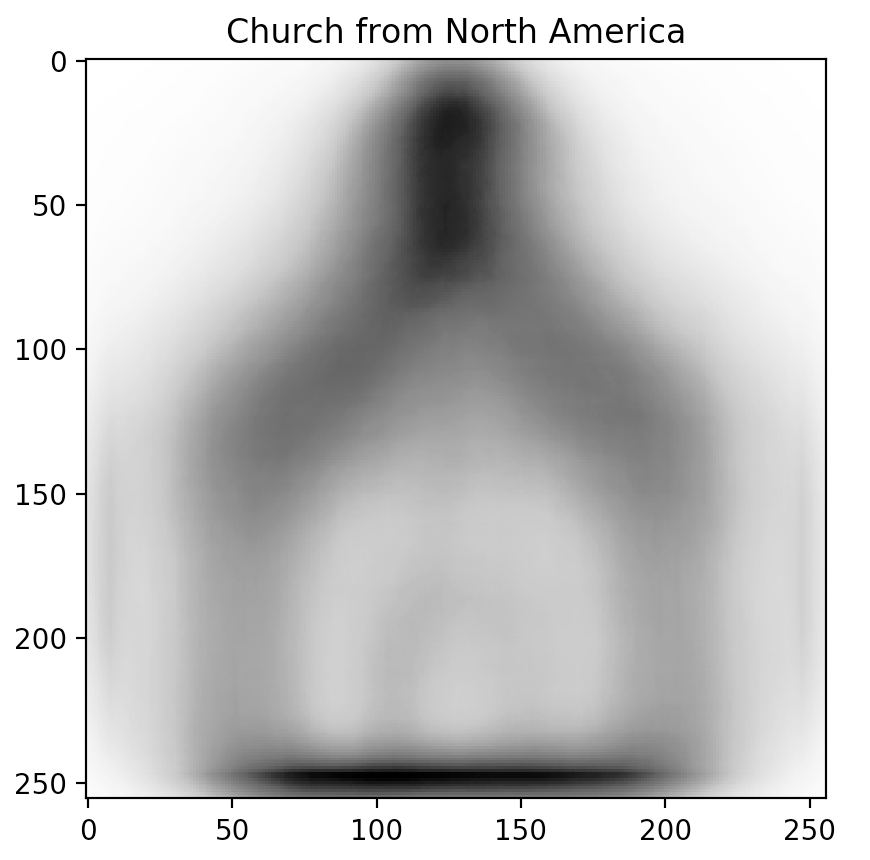
Is there a difference? These blended images speak for themselves.
Pseudo-Ensemble Probabilistic Model with Naive Bayes
Suppose we select the top N models to independently make inferences on the players drawings for each model category.
Under the Naive Bayes assumption (reference), we have:
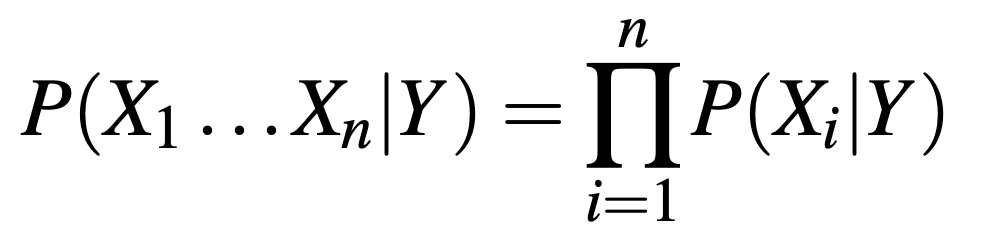
With the expression for the probability that Y will take on its kth possible value given our observations being:
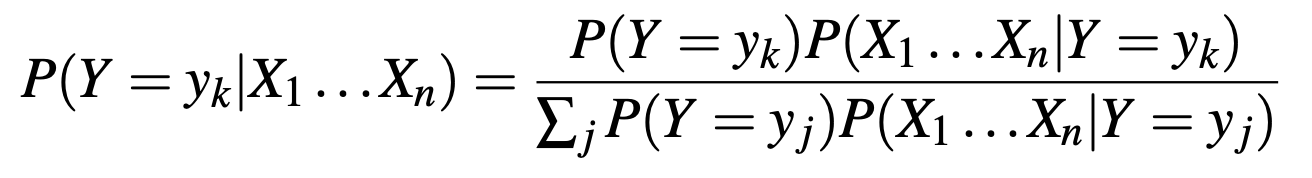
And finally, to make the prediction, we simply take the argmax of the multiplied probabilities:
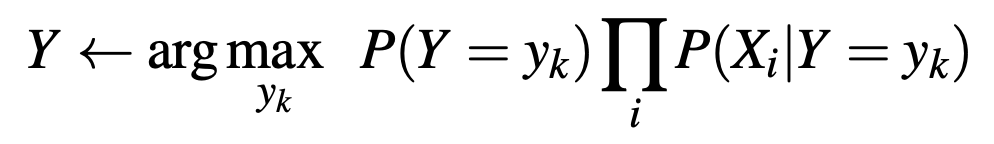
This concludes our method for using the Naive Bayes method as a means of leveraging multiple models in an ensemble-like fashion.